Programmatic Jenkins jobs using the Job DSL plugin ¬
Jenkins is an incredibly powerful and versatile tool but it can quickly become a maintenance nightmare: jobs are abandoned, lack of standardization, misconfiguration, etc. But it doesn’t have to be this way! By using the Jenkins Job DSL plugin you can take back control of your Jenkins installation.
It always starts off so simple: you just shipped a couple of nasty bugs that should have been caught and decide it’s high time to jump on board the Continuous Integration train. You have a single application and repository so this should be pretty easy. You fire up a Jenkins instance, manually create the first set of jobs using the build commands you were running locally, and everything is humming along just fine. You lean back, put your feet up, and watch as Jenkins runs your impossibly-comprehensive test suite and prevents you from ever shipping another bug again.
Fast-forward two years and now you have a service-oriented architecture spread across a couple dozen repositories. Each of these repositories has its own set of Jenkins jobs, and, despite being based off an initial template, they’ve all deviated in subtle and not-so-subtle ways. Some jobs (for instance, the pull request builder) should be nearly identical for each repository; the only differences are the repository being built and the email address who will receive the scathing build break email. The pain now becomes apparent when you need to make a change across all these jobs. For example, you realize that keeping the results of those pull requests from two years ago does nothing but take up disk space. Rather than edit all these jobs by hand you think “there must be a better way”, and you’re correct. Enter the Job DSL plugin.
Background
The Job DSL plugin really consists of two parts: A domain-specific language (DSL) that allows us to define job parameters programmatically and a Jenkins plugin to actually turn that DSL into Jenkins jobs. The plugin has the ability to run DSL code directly or to execute a Groovy script that contains the DSL directives.
Here is a trivial example of what the DSL looks like:
job('DSL-Test') {
steps {
shell('echo "Hello, world!"')
}
}This creates a new Freestyle job named “DSL-Test” and contains a single “Execute shell” build step. This is known as as the “seed job” since it is used to create other jobs and is the only job you’ll need to manage manually. Before proceeding let’s put this into action:
- Create a new Freestyle job
- Add a new build step and use the “Process Job DSLs” option
- Select “Use the provided DSL script” and paste the above snippet in the textarea
The configuration should look something like the following:
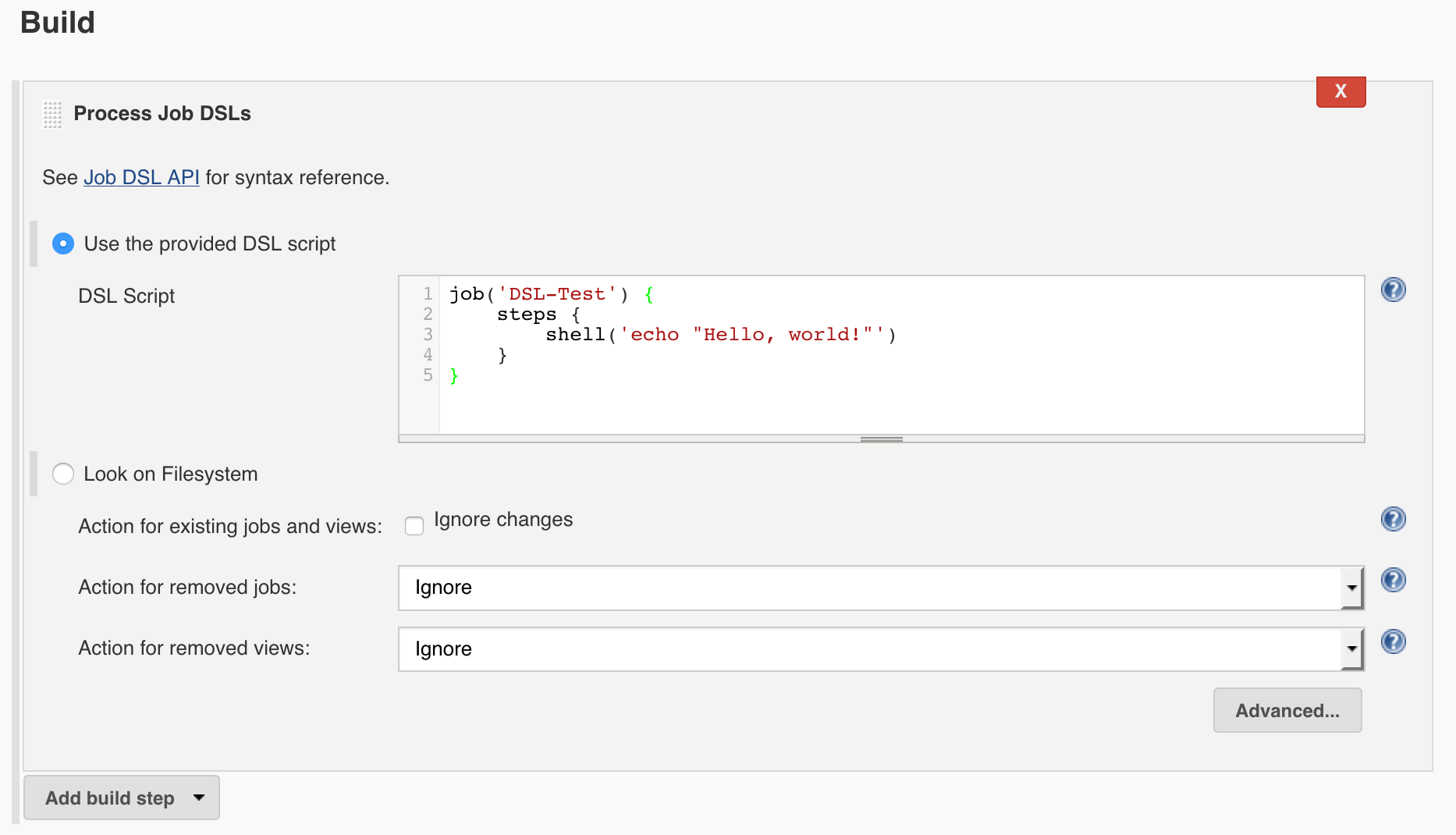
After running the seed job it will report the jobs it created both in the console output as well as the summary page. Further, any jobs that were created by the seed job will indicate they are managed by this job on their summary page.
Congratulations, you’re well on your way to DSL scorcery!
Now that we’ve got a handle on the basic usage let’s take it a step further. I’ll now show how we tamed our jobs by using a simple configuration file to drive the jobs being created.
Configuration
As hinted at above, the Curalate codebase is now spread across many repositories and we needed a fast and straightforward way to create and modify the Jenkins jobs that acted on these repositories. To that end we designed a YAML configuration file that would be used when creating the jobs:
project: Banana Stand
repo: curalate/banana-stand
email: gmb@curalate.comAny parameter that can differ between jobs can be defined here. As all our services and projects are written in Scala and built with Maven there is little differentiation currently. However, this is designed to be flexible enough to support future projects that don’t conform to these parameters. We aimed to strike a balance between ultimate flexibility and a sprawling configuration file.
In order to make working with the YAML file easier we’ve also created a small value object that will be populated with the values of the YAML above:
package models
/**
* Simple value object to store configuration information for a project.
*
* Member variables without a value defined are required and those with a value
* defined are optional.
*/
class ProjectConfig {
/*
* Required
*/
String project
String repo
String email
/*
* Optional
*/
String command_test = "mvn clean test"
}As we’ll see below, we use SnakeYAML to read in the configuration file and create the ProjectConfig instance.
Template
The template below is where we actually define the parameters of the job. In this case it’s a GitHub pull request builder. It will listen for pings from GitHub’s webhooks, run the test command (as defined in the configuration), and then set the build result on the pull request. We also define a few other parameters such as allowing concurrent builds, discarding old build information, and setting a friendly description. This is just a very small sample of what the DSL can do but it is very close to what we actually use for our pull request template internally. The Job DSL wiki is an excellent resource for more advanced topics and the API Viewer is indespensible for figuring out that obscure directive.
package templates
class PullRequestTemplate {
static void create(job, config) {
job.with {
description("Builds all pull requests opened against <code>${config.repo}</code>.<br><br><b>Note</b>: This job is managed <a href='https://github.com/curalate/jenkins-job-dsl-demo'>programmatically</a>; any changes will be lost.")
logRotator {
daysToKeep(7)
numToKeep(50)
}
concurrentBuild(true)
scm {
git {
remote {
github(config.repo)
refspec('+refs/pull/*:refs/remotes/origin/pr/*')
}
branch('${sha1}')
}
}
triggers {
githubPullRequest {
cron('H/5 * * * *')
triggerPhrase('@curalatebot rebuild')
onlyTriggerPhrase(false)
useGitHubHooks(true)
permitAll(true)
autoCloseFailedPullRequests(false)
}
}
publishers {
githubCommitNotifier()
}
steps {
shell(config.command_test)
}
}
}
}Seed job
Lastly, we need some glue to tie it all together and that’s where the seed job comes in. Rather than define the seed job inline as we did above we’re using a Groovy script that is stored in the repository. This moves more of the code outside of the Jenkins job and into version control. We’ve configured this seed job to run periodically on a schedule as well as after every commit. This ensures that the jobs it manages never deviate for too long from their configuration.
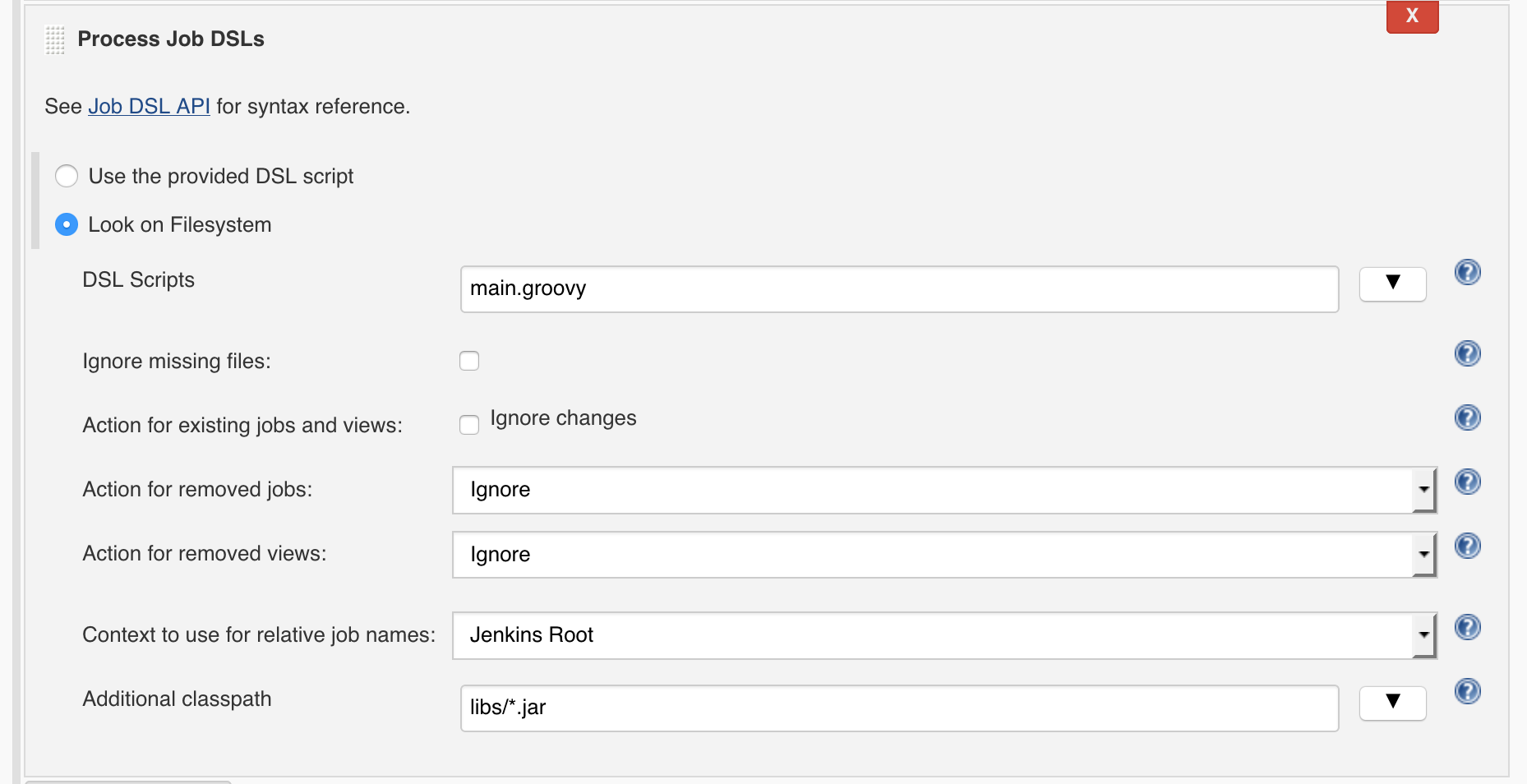
Before we can jump into the actual Groovy code we first need to make sure we can parse the YAML configuration files. For that, we’ll be using SnakeYAML. Since this library isn’t available by default it needs to be manually included. Thankfully, the plugin authors already thought of this and have the situation covered. To include the SnakeYAML library we add an initial “Execute shell” build step and download the library directly from Maven central into a ./libs directory:
#!/bin/bash
mkdir -p libs && cd libs
if [ ! -f "snakeyaml-1.17.jar" ]; then
wget https://repo1.maven.org/maven2/org/yaml/snakeyaml/1.17/snakeyaml-1.17.jar
fiThe next step in the seed job is to execute the DSL script. Notice that we’re using main.groovy as the entry point and we instruct the plugin to look for additional libraries in the ./libs directory that was created in the previous build step.
Now that we’ve got the foundation in place we can finally take a look at the contents of the main.groovy script. This is a single entry point where all our programmatic jobs are created.
import models.*
import templates.*
import hudson.FilePath
import org.yaml.snakeyaml.Yaml
import org.yaml.snakeyaml.constructor.CustomClassLoaderConstructor
createJobs()
void createJobs() {
def constr = new CustomClassLoaderConstructor(this.class.classLoader)
def yaml = new Yaml(constr)
// Build a list of all config files ending in .yml
def cwd = hudson.model.Executor.currentExecutor().getCurrentWorkspace().absolutize()
def configFiles = new FilePath(cwd, 'configs').list('*.yml')
// Create/update a pull request job for each config file
configFiles.each { file ->
def projectConfig = yaml.loadAs(file.readToString(), ProjectConfig.class)
def project = projectConfig.project.replaceAll(' ', '-')
PullRequestTemplate.create(job("${project}-Pull-Request"), projectConfig)
}
}In this example we run the following steps:
- Look in the
./configsdirectory for all files ending in.yml - Parse each YAML configuration file and create an instance of
ProjectConfig - Create an instance of
PullRequestTemplate, passing in the configuration instance
While I’ve left out some additional steps we take (such as creating dashboards for each project) the overall structure and code is very similar.
Conclusion
Using the above structure, a few days of work, and a hundred lines of code we were able to transform dozens of manual jobs into a set of coherent, standardized, and source-controlled jobs. The use of source control has also allowed us to set the seed job to automatically build when a new change is merged. So not only do we get the benefit of peer review before a change is merged but that change is deployed and available within mere seconds after it is merged. This speed combined with the DSL and Groovy scripting ability make this an incredibly powerful paradigm. All the code presented here is available in the jenkins-job-dsl-demo repository on GitHub so feel free to use it as a jumping off point.
Are we doing it wrong? Did we miss something? Come join us and help solve challenging problems. We’re hiring in Philadelphia, Seattle, and New York.

Rich Schumacher is a full-stack developer with an interest in infrastructure and distributed systems. He is currently leading the emerging DevOps team at Curalate and has fully converted to the church of Jenkins. In his spare time he is a big fan of hanging out with his family, running long distances, and playing with model trains.