Brewing EmojiNet ¬
Emojis, the tiny pictographs in our phone’s keyboard, have become a important form of communication. Even Oxford Dictionary named 😂 the word of the year for 2015. Though maybe not worth a thousand words, each emoji evokes a much richer response for the reader than boring old text. This makes sense: people communicate visually.
But what do emojis mean? Inspired by Instagram’s textual analysis of emoji hashtags, we set out to help answer this question in a more visual way. Our core question is simple: if people use emojis to describe images, is there a connection between the emoji and the visual content of the image? For some emojis like 🍕 or 🐕, we expect that the emoji describes the content of the image. But what about a less obvious emoji like 💯 or ✊ ?
We investigate these questions by turning to the latest craze in computer vision: deep learning. Deep learning lets you train an entire model with low-, mid-, and high-level representations all at once. This comes at the expense of requiring a large amount of training data. For this investigation, we wish to train a model that suggests emojis for a given image. The deep learning technique typically used for computer vision is convolutional neural networks, and thus we call our model EmojiNet.
Our resulting model powered the Curalate Emojini, a fun app that suggests emojis for your images:
 |
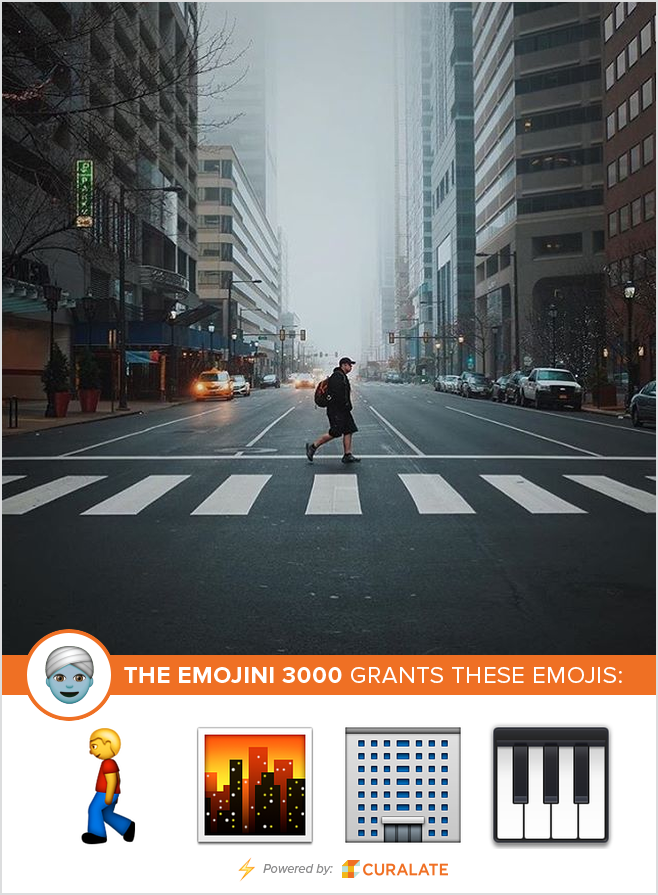 |
 |
We have since taken down the website to save some costs (we are a startup!), but here I’ll discuss a few of EmojiNet’s technical details and present some of the more interesting visual meanings people associate with emojis. As with most of our services, we require a high degree of buzzword compliance: the Emojini uses an asynchronous web service deployed in the cloud that executes our deep learning model on GPUs.
Emojis Assemble
Our first task was to gather a large corpus of training images associated with emojis. Fortunately, Instagram provides a very extensive api and tends to have a large number of users hashtagging with emojis.
The most common emoji set contains 845 characters in Unicode 6.1. More recent sets contain many more emojis, but they may not be available on all platforms. IOS 9.1, for example, contains 1,620 emojis. For this investigation, we chose to focus on the most common emojis on Instagram. Thus, we hit the Instagram’s tags endpoint with the 845 base emojis. This returns the number of Instagram media with a hashtag of the requested emoji. When we gathered our data in the fall of 2015, the ❤ emoji was the most popular with over a million posts containing it. The distribution was rather skewed, with many emojis such as 📭 and 🈺 having less than 100 posts, and others none at all.
To ensure we have enough training data, we chose to only train our system on the 500 most popular emojis used on Instagram. As a result, EmojiNet doesn’t know about many newer emojis such as crab, hugging-face, or skin-tone modifiers
Next, we used the tag’s recent media endpoint to download images that contained specific emoji hashtags. This endpoint returns public Instagram posts that contain the given hashtag in the post’s caption or comments section. To ensure quality, we only keep posts that had five or fewer hashtags and contained the emoji we searched for in the caption.
Finally, we only mined a few thousand images from each tag. This ensures that the system isn’t over-trained on high frequency emoji and reduced our computational costs.
The resulting data set has 1,075,376 images, each associated with one or more of the 500 top emojis.
Learn Baby, Learn
🆒. We have our data. Let’s train EmojiNet. Like any good computer vision scientist, we used the Caffe framework to train a deep convolutional neural network to suggest emojis.
We framed the problem as a simple classification: the net should return a 500-dimensional vector containing the likelihood of the input image being associated with each emoji.
We trained the net on an Amazon g2.2xlarge instance running Ubuntu 14.04.
These boxes have an Nvidia K520 which, while not the fastest cards on the market, have reasonable performance.
We installed Cuda 6.5 and cuDNN v2, and compiled Caffe to link against them (note: Caffe now requires Cuda 7 and cuDNN version 3).
As with most GPU-bound tasks, true speed-up is dependent on how fast you can get data to the GPU.
Caffe supports reading images from disk or an lmdb database.
The database images can be compressed or uncompressed, while on-disk images can be pre-scaled to the input layer size or not.
We did a bit of off-the-cuff benchmarking to see what pre-processing/data store was the best for Caffe on ec2. To measure this, we used the Caffe benchmarking tool, which measures the average forwards/backwards pass over the neural net in milliseconds. Below are the timings for a batch size of 256 images:
| Database | Compression | Scaled | Time (ms) |
|---|---|---|---|
| lmdb | jpg | yes | 1681.84 |
| lmdb | none | yes | 1683.32 |
| on disk | jpg | yes | 1682.05 |
| on disk | jpg | no | 1918.49 |
Interestingly, using lmdb provided little speedup over on-disk jpeg images.
Whether or not the images are compressed to jpeg in the lmdb database also seems to have little impact.
The big speed-up comes from prescaling images (which must be done if you use lmdb).
For EmojiNet, we used an on-disk data set of pre-scaled jpeg images.
This was slightly easier to manage than writing everything to lmdb, and still provided a decent footprint on disk and fast processing time. We used mogrify and
xargs to pre-scale the images in parallel.
Rather than training the net from scratch, we used a common technique called fine-tuning. The idea is to start with a net trained on other images (in this case, the 14 million images in ImageNet), and execute the training with reduced weights on the earlier layers. This worked well for the EmojiNet, although it steered the net towards semantic biases in many cases, as discussed below. We trained EmojiNet for about a quarter-million iterations (about a week wall clock time) using a batch size of 256 images.
The EmojiNet Web Service
After training EmojiNet, we wanted to build a scalable web service to handle all of your awesome Instagram photos. This presents an interesting engineering challenge: how can we use modern web service models with a GPU-bound computation? Two key principles we adhere to when building web services are:
- Asynchronous processing to make the most out of the server’s resources.
- Auto-scaling based on load.
The Caffe software is great for loading up a bunch of data and trying to train a classifier, but not as great at managing concurrent classification requests.
To build a scalable web service, we used an akka actor to lock access to the GPU.
That way, only one process may access the GPU at a time, but we get the illusion of asynchronous operations via the ask pattern.
In addition, we can directly measure how long a process waits for the GPU to be unlocked. We publish this measure to Amazon’s CloudWatch and use it as a trigger on the auto-scaling group.
Below is a Scala example of our actor:
object EmojiNetActor {
val instance = actorSystem.actorOf(Props(new EmojiNetActor))
}
private class EmojiNetActor() extends Actor {
def receive: Receive = {
case ClassificationRequest(images, queueTime) => {
// Compute how long the message was queued for
val waitTime = System.currentTimeMillis - queueTime
// Publish the wait time to CloudWatch
cloudwatch.putMetricData(...)
// Hit the GPU and compute results
val emojis = emojiNet.classifyImages(images)
// send the results to the requesting process
sender ! ClassificationResults(emojis, waitTime)
}
}
}
case class ClassificationRequest(images: List[BufferedImage], queueTime: Long)The singleton pattern provides one actor per JVM process and thus locks the GPU.
Finally, we use the ask pattern to provide the illusion of asynchronous operations:
implicit val timeout = Duration(1, "second")
def classifyImages(images: List[BufferedImage]): Future[EmojiResult] = {
val request = ClassificationRequest(images, System.currentTimeMillis)
EmojiNetActor.instance.ask(request).map {
case x: EmojiResult => x
case x: AnyRef => throw new RuntimeException(s"Unknown Response $x")
}
}Thus, we get an asynchronous call to a locked resource (the GPU) and the back-pressure to the actor is published to CloudWatch and read by our auto-scaling group. That way, we scale out as the GPUs get backed up.
The EmojiNet web service has found it’s way into a few other places than just Emojini.
Tim Hahn, one of our software engineers, wrote a hubot script we’ve made available on github that gives us EmojiNet integration with slack:

Insights
So, what do emojis mean? One of the fascinating things about the results are the visual characteristics that become associated with each emoji. To see this, we looked at the images with the highest confidence value for specific emoji.
As expected, semantic associations are well captured. This is primarily due to users associating tags with their visual counterparts, but is amplified by the fact that we trained with a base semantic net. Pictures of pizza, for instance, are strongly associated with the pizza emoji 🍕:

The non-semantic associations, however, are far more interesting. Specifically, the neural net captures what visual characteristics of the image are associated with each emoji. Many emojis may not have a clear meaning in terms of a traditional language, but are still associated with specific visual content.
Face With Tears of Joy 😂, for example, is associated with images of memes:

What’s fascinating here is that the EmojiNet can apply an emotional response even though it has no knowledge of the context or subject matter. This is the AI equivalent of a baby laughing at The Daily Show: it doesn’t understand why it’s funny.
Also of interest is when an emoji is co-opted by a social trend. Raised Fist ✊, for example, is described by Emojipedia as commonly “used as a celebratory gesture.” The Instagram community, however, has associated it with dirt bikes:

Similarly, the syringe 💉 is often used for tattoos:

We even see examples of brands snagging emojis. The open hands 👐 has been snagged by Red Bull. We can only assume it’s because they look like wings.

Thankfully, other emoji have become visually associated with themselves:
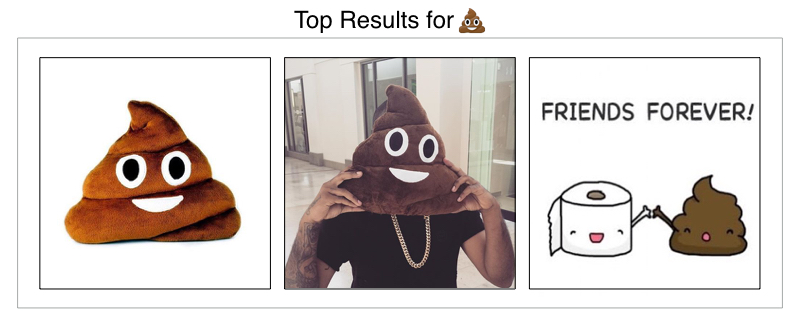
What’s really interesting about these results is that society has assigned specific meanings to emojis, even when they weren’t the intention of the emoji creator. This makes the Curalate Emojini all the more fun: even unexpected results tell a story about how the Instagram community views a specific image. The EmojiNet demonstrates that such socially attributed meanings have clear visual cues, indicating that emojis themselves are evolving into their own visual language.

Lou Kratz is the Lead Research Engineer at Curalate. He received his PhD in computer vision from Drexel University in 2012, and then got hit by the start-up bug in the best way. He enjoys making cool stuff using computer vision and machine learning when he's not cooking, watching Jeopardy, or playing bocce. He lives in Philadelphia which he used as a primary subject for his instagram account, at least until his daughter was born.