R&D At Curalate: A Case Study of Deep Metric Embedding ¬
At Curalate, we make social sell for hundreds of the world’s largest brands and retailers. Our Fanreel product is a good example of this; it empowers brands to collect, curate, and publish social user-generated photos to their e-commerce site. A vital step in this pipeline is connecting the user generated content (UGC) to the product on our client’s web site. Automating this process requires cutting edge computer vision techniques whose implementation details are not always clear, especially for production use cases. In this post, I review how we leveraged Curalate’s R&D principles to build a visual search engine that identifies which of our clients’ products are in user generated photos. The resulting system allows our clients to quickly connect user generated content to their e-comm site, enabling the UGC to generate revenue immediately upon distribution.
Step 1: Do Your Homework
We start every R&D project by hitting the books and catching up on the relevant research. This lets us understand what is feasible, the (rough) computational costs, and any pitfalls of various techniques. In this case, our goal is to find which products are in any UGC image using only the product images from the client’s e-comm site. This is extremely difficult: UGC photos have dramatic lighting conditions, generally contain multiple objects or clutter, and may have undergone non rigid transformations (especially if it’s a garment). Knowing we had a difficult problem on our hands, we did an extensive literature review on papers from leading computer vision conferences, journals, and even arxiv to ensure we have a good understanding of the state of the art.
One approach stood out in the literature review: deep metric learning. Deep metric learning is a deep learning technique that learns an embedding function that, when applied to images of the same product, produces feature vectors that are close together in Euclidean space. This technique is perfect for our use case: we can train the system from existing pairs of UGC and product images in our platform to understand the complex transformations products undergo in UGC photos.
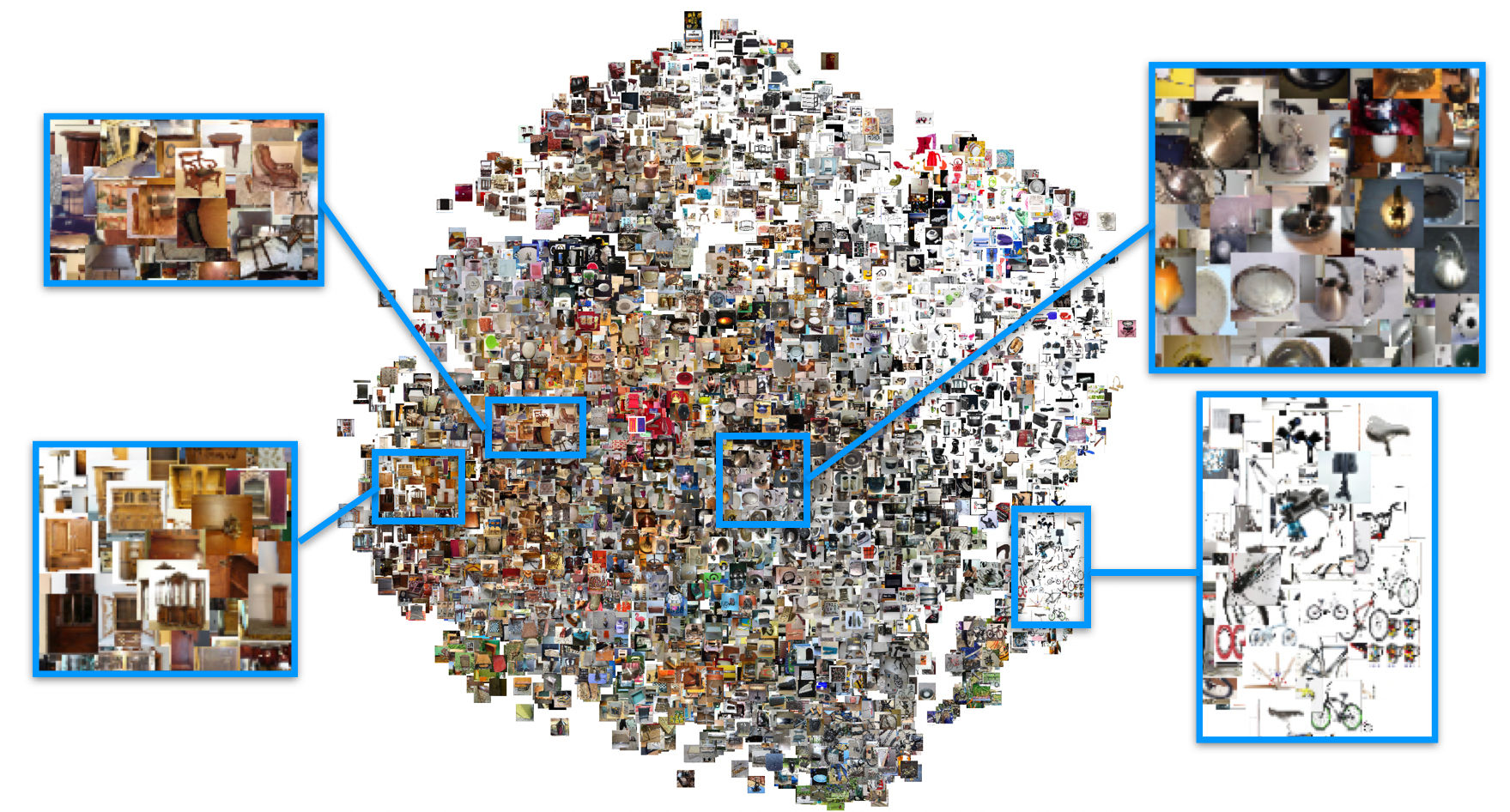
The figure above (from Song et. al.) shows a t-SNE visualization of a learned embedding of the Stanford Online Products dataset. Notice that images of similar products are close together: wooden furniture zoomed in on the upper left, and bike parts on the lower right. Once we’ve learned this embedding function, identifying the products in a UGC image can be achieved by finding which embedding vectors from the client’s product photos that are closest to that of the UGC.
Most techniques for deep metric learning start with a deep convolutional neural network trained on imagenet (i.e., a basenet), remove the final classification layer, add a new layer that performs a projection to the n-dimensional embedding space, and fine-tune it with an appropriate loss function. One highly cited work is Facenet by Schroff et. al., who propose a loss function that uses triplets of images. Each triplet contains an anchor image, a positive example that is the same class as the anchor, and a negative match that is a different class than the anchor image. Though more recent work has surpassed Facenet, in interest of speed (we are a startup!) we decided to take it for a spin since a tensorflow implementation was available online.
Step 2: Prototype and Experiment
The second phase of an R&D project at Curalate is the prototype phase. In this phase, we implement our chosen approach as fast as possible, and evaluate it on publically available data as well as our own. As with many things in a startup, speed is key here. Specifically, we need answers as fast as possible so we know what we need to build. This phase is designed to answer the question: will it work and, if so, how well? In addition, this phase is when we experiment with different implementation details of techniques we wish to implement. Hyper parameter tuning, architecture components, and comparing different algorithms all occur in this phase of R&D.
The big question we want to answer for our deep metric embedding project is: which basenet should we use? The Facenet paper used GoogLeNet inception models, but there have been many improvements since their publication. To compare different networks, we measure each of their performance on the Stanford Online Products dataset. We implemented Facenet’s triplet loss in MXNet so we can easily swap-out the underlying basenet.
We compared the following networks from the MXNet Model Zoo:
A secondary question we wished to answer with this experiment was how efficiently we could compute the embeddings. To explore this, we also evaluated two smaller, faster networks:
The figure above shows the recall-at-1 accuracy for all basenets. Not surprisingly, the more computationally expensive networks (i.e., Resnet-152 and SENet) have the highest accuracy. SENet, in particular, achieved a recall-at-1 of 71.6%, which is only two percentage less than the current state of the art.
One of the exciting results for us was squeezenet. Though it only achieved 60% accuracy, this network is extremely small (< 5MB) and computationally fast enough to run on a mobile phone. Thus we could sacrifice some accuracy for a huge savings in computational cost if we require it.
Step 3: Ship It
The final phase of an R&D project at Curalate is productization. In this phase, we leverage our findings from the prototype and literature phases to design and build a reliable and efficient production system. All code from the prototype phase is discarded or heavily refactored to be more efficient, testable, and maintainable. With deep learning systems, we also build a data pipeline for extracting, versioning, and snapshotting datasets from our current production systems.
For this project, we train the model on a P6000 GPU rented from paperspace.
We again use MXNet so the resulting model can be deployed directly to our production web services (which are
written in Scala).
We opted to use Resnet-152 as a basenet to get a high accuracy result, and deployed the learned network to g2.2xlarge instances on aws.
The visual search system we built powers our Intelligent Product Tagging feature, which you can see in the video below. Using deep metric embedding, we vastly increased the accuracy of intelligent product tagging compared to non-embedded deep features.

Lou Kratz is the Lead Research Engineer at Curalate. He received his PhD in computer vision from Drexel University in 2012, and then got hit by the start-up bug in the best way. He enjoys making cool stuff using computer vision and machine learning when he's not cooking, watching Jeopardy, or playing bocce. He lives in Philadelphia which he used as a primary subject for his instagram account, at least until his daughter was born.